Como funciona o robozinho do Serenata que baixa os diários oficiais?
Thu 28 November 2019Recentemente comecei a fazer parte do programa de embaixadores da Open Knowledge Brasil (OKBR). Como minha primeira contribuição, comecei adicionar novos spiders no diario-oficial. Esse repositório possui diversos spiders para a raspagem de dados dos diários oficiais de cada município brasileiro. Como sou de Santa Catarina, decidi inicial com as cidades do meu Estado. Felizmente, no tempo de escrita deste artigo, minha primeira pull request está aguardando aprovação! :)
Durante esse meio tempo, outros embaixadores demonstraram interesse em adicionar ou modificar os spiders para suas cidades. Ai que entra esse artigo... eu pretendo explicar na forma mais didática que eu conseguir, tudo o que é necessário para começar a entender como adicionar ou alterar um spider. Para isso, irei explicar como funciona cada parte necessária para isso. Incluindo como baixar o código, como rodar um spider, um pouco de python, Scrapy, HTML, entre outros. Não pretendo ser muito técnico para deixar o documento mais acessivel possível. Mas também não muito superficial que não diga nada. Ou seja, existe a possiblidade de não agradar ninguém. xD.
Por favor, entre em contato se sentir falta de algo! Então vamos lá...
diario-oficial
O projeto diario-oficial da OKBR, tem como objetivo realizar a raspagem de dados dos diário oficiais do maior número de municípios brasileiros possíveis. Como fazemos isso? Bom, os diários oficiais são distribuídos em arquivos doc, pdf e etc. Para conseguir ter todos esses arquivos utilizamos um robozinho que literalmente abre todas as páginas dos diários oficiais de cada município e baixa todos esses arquivos. Uma vez com os arquivos baixados, convertemos eles em texto (arquivos txt) e pronto! Depois disso podem ser analisados mais facilmente com as mágicas da ciência de dados! :-)
Antes de mais nada vamos rodar um spider para ver como funciona. Depois vamos ver como ele é escrito. Para baixar o projeto você ira precisar do git. A instalação do git vai variar de acordo com seu ambiente. Veja a documentação sobre a instalação aqui. Se precisar de ajuda, não deixe de falar nos canais de comunicação dos Embaixadores ou do Serenata. Podemos ajudar por lá! Aliás, esse artigo será todo baseado no meu ambiente, que é um Linux. Não creio que vão existir grandes diferenças entre os sistemas que possa impossibilitar de seguir esse material. A principal diferença, acredito, que seja como irá baixar o repositório do projeto. Mas como disse anteriormente, não hesite em perguntar!
Blz, uma vez com o gitinstalado precisamos baixar o repositório, ou seja o código que o robozinho ira executar. Para isso, vá até a página do projeto no github e copie a URL:
Uma vez com a URL podemos clonar o repositório. Clonar é um termo do git que basicamente é um sinônimo para baixar um repositório:
jvanz@earth:~> git clone https://github.com/okfn-brasil/diario-oficial.git
Cloning into 'diario-oficial'...
remote: Enumerating objects: 30, done.
remote: Counting objects: 100% (30/30), done.
remote: Compressing objects: 100% (21/21), done.
remote: Total 2253 (delta 13), reused 19 (delta 9), pack-reused 2223
Receiving objects: 100% (2253/2253), 11.68 MiB | 7.04 MiB/s, done.
Resolving deltas: 100% (1320/1320), done.
Agora que você já tem o código fonte na sua máquina, podemos executar algum spider que já existe. Os spider já existentes podem ser encontrados no diretório processing/data_collection/gazette/spiders/:
jvanz@earth:~/diario-oficial> ls processing/data_collection/gazette/spiders/
al_maceio.py base.py go_goiania.py pr_cascavel.py pr_maringa.py rr_boa_vista.py sp_campinas.py sp_jundiai.py to_palmas.py
am_manaus.py ce_fortaleza.py __init__.py pr_curitiba.py pr_ponta_grossa.py rs_caxias_do_sul.py sp_franca.py sp_santos.py
ba_feira_de_santana.py es_associacao_municipios.py mg_uberaba.py pr_foz_do_iguacu.py rj_rio_de_janeiro.py rs_porto_alegre.py sp_guaruja.py sp_sao_jose_dos_campos.py
ba_salvador.py go_aparecida_de_goiania.py ms_campo_grande.py pr_londrina.py ro_porto_velho.py sc_florianopolis.py sp_guarulhos.py to_araguaina.py
jvanz@earth:~/diario-oficial>
Agora que já sabemos quais sãos as cidades já mapeadas, vamos rodar nosso robozinho para baixar os arquivos? Para rodar o robozinho e baixar os arquivos de Florianópolis - SC, podemos executar o seguinte comando:
$ docker-compose run --rm processing bash -c "cd data_collection && scrapy crawl sc_florianopolis"
Note que para executar o nosso robô, precisamos instalar o docker e o docker-comose. Veja como instala-los aqui e aqui
Você provavelmente irá ver algo parecido com isso:
2019-11-26 01:40:56 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: gazette)
2019-11-26 01:40:56 [scrapy.utils.log] INFO: Versions: lxml 4.4.1.0, libxml2 2.9.9, cssselect 1.1.0, parsel 1.5.2, w3lib 1.21.0, Twisted 19.10.0, Python 3.6.8 (default, Jun 11 2019, 01:16:11) - [GCC 6.3.0 20170516], pyOpenSSL 19.0.0 (OpenSSL 1.1.1d 10 Sep 2019), cryptography 2.8, Platform Linux-4.12.14-lp151.28.20-default-x86_64-with-debian-9.9
2019-11-26 01:40:56 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'gazette', 'LOG_FILE': 'sc_florianopolis', 'NEWSPIDER_MODULE': 'gazette.spiders', 'SPIDER_MODULES': ['gazette.spiders']}
2019-11-26 01:40:56 [scrapy.extensions.telnet] INFO: Telnet Password: bc2ce55e70ec1566
2019-11-26 01:40:56 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.memusage.MemoryUsage',
'scrapy.extensions.logstats.LogStats']
2019-11-26 01:40:56 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2019-11-26 01:40:56 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2019-11-26 01:40:56 [scrapy.middleware] INFO: Enabled item pipelines:
['gazette.pipelines.GazetteDateFilteringPipeline',
'gazette.parser.GazetteFilesPipeline',
'scrapy.pipelines.files.FilesPipeline',
'gazette.pipelines.ExtractTextPipeline',
'gazette.pipelines.PostgreSQLPipeline']
2019-11-26 01:40:56 [scrapy.core.engine] INFO: Spider opened
2019-11-26 01:40:56 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2019-11-26 01:40:56 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2019-11-26 01:40:56 [scrapy.core.engine] DEBUG: Crawled (200) <POST http://www.pmf.sc.gov.br/governo/index.php?pagina=govdiariooficial> (referer: None)
2019-11-26 01:40:56 [scrapy.core.engine] DEBUG: Crawled (200) <POST http://www.pmf.sc.gov.br/governo/index.php?pagina=govdiariooficial> (referer: None)
2019-11-26 01:40:56 [scrapy.core.engine] DEBUG: Crawled (200) <POST http://www.pmf.sc.gov.br/governo/index.php?pagina=govdiariooficial> (referer: None)
2019-11-26 01:40:56 [scrapy.core.engine] DEBUG: Crawled (200) <POST http://www.pmf.sc.gov.br/governo/index.php?pagina=govdiariooficial> (referer: None)
2019-11-26 01:40:56 [scrapy.core.engine] DEBUG: Crawled (200) <POST http://www.pmf.sc.gov.br/governo/index.php?pagina=govdiariooficial> (referer: None)
2019-11-26 01:40:56 [scrapy.core.engine] DEBUG: Crawled (200) <POST http://www.pmf.sc.gov.br/governo/index.php?pagina=govdiariooficial> (referer: None)
2019-11-26 01:40:56 [scrapy.core.engine] DEBUG: Crawled (200) <POST http://www.pmf.sc.gov.br/governo/index.php?pagina=govdiariooficial> (referer: None)
2019-11-26 01:40:56 [scrapy.core.engine] DEBUG: Crawled (200) <POST http://www.pmf.sc.gov.br/governo/index.php?pagina=govdiariooficial> (referer: None)
2019-11-26 01:40:57 [scrapy.core.engine] DEBUG: Crawled (200) <POST http://www.pmf.sc.gov.br/governo/index.php?pagina=govdiariooficial> (referer: None)
2019-11-26 01:40:57 [scrapy.core.engine] DEBUG: Crawled (200) <POST http://www.pmf.sc.gov.br/governo/index.php?pagina=govdiariooficial> (referer: None)
2019-11-26 01:40:57 [scrapy.core.engine] DEBUG: Crawled (200) <POST http://www.pmf.sc.gov.br/governo/index.php?pagina=govdiariooficial> (referer: None)
2019-11-26 01:40:57 [scrapy.core.engine] DEBUG: Crawled (200) <POST http://www.pmf.sc.gov.br/governo/index.php?pagina=govdiariooficial> (referer: None)
2019-11-26 01:40:57 [scrapy.core.engine] DEBUG: Crawled (200) <POST http://www.pmf.sc.gov.br/governo/index.php?pagina=govdiariooficial> (referer: None)
2019-11-26 01:40:57 [scrapy.core.engine] DEBUG: Crawled (200) <POST http://www.pmf.sc.gov.br/governo/index.php?pagina=govdiariooficial> (referer: None)
2019-11-26 01:40:57 [scrapy.core.engine] DEBUG: Crawled (200) <POST http://www.pmf.sc.gov.br/governo/index.php?pagina=govdiariooficial> (referer: None)
2019-11-26 01:40:57 [scrapy.core.engine] DEBUG: Crawled (200) <POST http://www.pmf.sc.gov.br/governo/index.php?pagina=govdiariooficial> (referer: None)
2019-11-26 01:40:57 [scrapy.core.engine] DEBUG: Crawled (200) <POST http://www.pmf.sc.gov.br/governo/index.php?pagina=govdiariooficial> (referer: None)
2019-11-26 01:40:57 [scrapy.core.engine] DEBUG: Crawled (200) <POST http://www.pmf.sc.gov.br/governo/index.php?pagina=govdiariooficial> (referer: None)
2019-11-26 01:40:57 [scrapy.core.engine] DEBUG: Crawled (200) <POST http://www.pmf.sc.gov.br/governo/index.php?pagina=govdiariooficial> (referer: None)
2019-11-26 01:40:57 [scrapy.core.engine] DEBUG: Crawled (200) <POST http://www.pmf.sc.gov.br/governo/index.php?pagina=govdiariooficial> (referer: None)
2019-11-26 01:40:57 [scrapy.core.engine] DEBUG: Crawled (200) <POST http://www.pmf.sc.gov.br/governo/index.php?pagina=govdiariooficial> (referer: None)
2019-11-26 01:40:57 [scrapy.core.engine] DEBUG: Crawled (200) <POST http://www.pmf.sc.gov.br/governo/index.php?pagina=govdiariooficial> (referer: None)
2019-11-26 01:40:57 [scrapy.core.engine] DEBUG: Crawled (200) <POST http://www.pmf.sc.gov.br/governo/index.php?pagina=govdiariooficial> (referer: None)
2019-11-26 01:40:57 [scrapy.core.engine] DEBUG: Crawled (200) <POST http://www.pmf.sc.gov.br/governo/index.php?pagina=govdiariooficial> (referer: None)
2019-11-26 01:40:58 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.pmf.sc.gov.br/arquivos/diario/pdf/18_11_2019_20.19.06.6b3ba3f7d8914621f5065d4d0f6c9d5e.pdf> (referer: None)
2019-11-26 01:40:58 [scrapy.pipelines.files] DEBUG: File (downloaded): Downloaded file from <GET http://www.pmf.sc.gov.br/arquivos/diario/pdf/18_11_2019_20.19.06.6b3ba3f7d8914621f5065d4d0f6c9d5e.pdf> referred in <None>
2019-11-26 01:40:58 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.pmf.sc.gov.br/arquivos/diario/pdf/18_11_2019_23.01.36.df3583c76e3e2ce083a2275cf3e9adbe.pdf> (referer: None)
2019-11-26 01:40:58 [scrapy.pipelines.files] DEBUG: File (downloaded): Downloaded file from <GET http://www.pmf.sc.gov.br/arquivos/diario/pdf/18_11_2019_23.01.36.df3583c76e3e2ce083a2275cf3e9adbe.pdf> referred in <None>
2019-11-26 01:40:58 [scrapy.pipelines.files] DEBUG: File (uptodate): Downloaded file from <GET http://www.pmf.sc.gov.br/arquivos/diario/pdf/18_11_2019_20.19.06.6b3ba3f7d8914621f5065d4d0f6c9d5e.pdf> referred in <None>
2019-11-26 01:40:58 [scrapy.pipelines.files] DEBUG: File (uptodate): Downloaded file from <GET http://www.pmf.sc.gov.br/arquivos/diario/pdf/18_11_2019_23.01.36.df3583c76e3e2ce083a2275cf3e9adbe.pdf> referred in <None>
2019-11-26 01:40:58 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.pmf.sc.gov.br/governo/index.php?pagina=govdiariooficial>
{'date': datetime.date(2019, 11, 18),
'file_checksum': 'f24ca0401f64b6de3dc8a647dcbbea52',
'file_path': 'full/c7955799d47d4fe59b6f582dad4b5c172508dac9.pdf',
'file_url': 'http://www.pmf.sc.gov.br/arquivos/diario/pdf/18_11_2019_20.19.06.6b3ba3f7d8914621f5065d4d0f6c9d5e.pdf',
'is_extra_edition': False,
'power': 'executive_legislature',
'scraped_at': datetime.datetime(2019, 11, 26, 1, 40, 57, 88559),
'source_text': ' DIÁRIO OFICIAL ELETRÔNICO\n'
' DO MUNICÍPIO DE '
'FLORIANÓPOLIS\n'
'Edição Nº 2568 Florianópolis/SC, '
'segunda-feira, 18 de novembro de '
'2019 '
'pg. 1\n'
' '
'Sumário: '
'Administrativo e Financeiro, lotado na Secretaria\n'
'Orgãos '
'Municipais '
'Pg. Municipal da Casa Civil, matrícula 49327-9,\n'
'SECRETARIA MUNICIPAL DA CASA '
'CIVIL 1\n'
' '
'devidamente habilitado pela CNH sob nº\n'
' '
'05084675850, categoria AB. Art. 2º A\n'
'SECRETARIA MUNICIPAL DE '
'ADMINISTRAÇÃO 1\n'
' '
'responsabilidade administrativa, civil e penal, em\n'
'SECRETARIA MUNICIPAL DA FAZENDA '
'2 caso de colisões, lesões '
'corporais ou mesmo óbitos\n'
'SECRETARIA MUNICIPAL DE TRANSPARÊNCIA,AUDITORIA '
'E decorrentes do objetivo desta '
[...]
Texto omitido porque é MUITA coisa
[...]
'Portaria, qual seja,\n'
'CONTROLE '
'4 autorizar a condução do '
'automóvel da Secretaria\n'
'SECRETARIA MUNICIPAL DE '
'EDUCAÇÃO 5 '
'Municipal da Casa Civil, conforme termo de\n'
'SECRETARIA MUNICIPAL DE '
'INFRAESTRUTURA 6 '
'\n'
'\n'
'\n'
'S.M.C.C.\n'
'SECRETÁRIO: EVERSON '
'MENDES CONTROLE: '
'THAMARA MALTA '
'TELEFONE: (48) 3251-6062\n'
'\x0c',
'territory_id': '4205407'}
2019-11-26 01:40:58 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.pm
Vamos dar uma analisada no que isso tudo significa.
Essa linha mostra qual é a página de web que o nosso robô está acessando e procurando os arquivos:
2019-11-26 01:40:56 [scrapy.core.engine] DEBUG: Crawled (200) <POST http://www.pmf.sc.gov.br/governo/index.php?pagina=govdiariooficial> (referer: None)
Esse são arquivos que ele encontrou e baixou:
2019-11-26 01:40:58 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.pmf.sc.gov.br/arquivos/diario/pdf/18_11_2019_20.19.06.6b3ba3f7d8914621f5065d4d0f6c9d5e.pdf> (referer: None)
2019-11-26 01:40:58 [scrapy.pipelines.files] DEBUG: File (downloaded): Downloaded file from <GET http://www.pmf.sc.gov.br/arquivos/diario/pdf/18_11_2019_20.19.06.6b3ba3f7d8914621f5065d4d0f6c9d5e.pdf> referred in <None>
2019-11-26 01:40:58 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.pmf.sc.gov.br/arquivos/diario/pdf/18_11_2019_23.01.36.df3583c76e3e2ce083a2275cf3e9adbe.pdf> (referer: None)
2019-11-26 01:40:58 [scrapy.pipelines.files] DEBUG: File (downloaded): Downloaded file from <GET http://www.pmf.sc.gov.br/arquivos/diario/pdf/18_11_2019_23.01.36.df3583c76e3e2ce083a2275cf3e9adbe.pdf> referred in <None>
2019-11-26 01:40:58 [scrapy.pipelines.files] DEBUG: File (uptodate): Downloaded file from <GET http://www.pmf.sc.gov.br/arquivos/diario/pdf/18_11_2019_20.19.06.6b3ba3f7d8914621f5065d4d0f6c9d5e.pdf> referred in <None>
2019-11-26 01:40:58 [scrapy.pipelines.files] DEBUG: File (uptodate): Downloaded file from <GET http://www.pmf.sc.gov.br/arquivos/diario/pdf/18_11_2019_23.01.36.df3583c76e3e2ce083a2275cf3e9adbe.pdf> referred in <None>
Da uma olhada nisso, aqui é texto extraido do arquivo baixado no site do diário oficial:
2019-11-26 01:40:58 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.pmf.sc.gov.br/governo/index.php?pagina=govdiariooficial>
{'date': datetime.date(2019, 11, 18),
'file_checksum': 'f24ca0401f64b6de3dc8a647dcbbea52',
'file_path': 'full/c7955799d47d4fe59b6f582dad4b5c172508dac9.pdf',
'file_url': 'http://www.pmf.sc.gov.br/arquivos/diario/pdf/18_11_2019_20.19.06.6b3ba3f7d8914621f5065d4d0f6c9d5e.pdf',
'is_extra_edition': False,
'power': 'executive_legislature',
'scraped_at': datetime.datetime(2019, 11, 26, 1, 40, 57, 88559),
'source_text': ' DIÁRIO OFICIAL ELETRÔNICO\n'
' DO MUNICÍPIO DE '
'FLORIANÓPOLIS\n'
'Edição Nº 2568 Florianópolis/SC, '
'segunda-feira, 18 de novembro de '
'2019 '
'pg. 1\n'
' '
'Sumário: '
'Administrativo e Financeiro, lotado na Secretaria\n'
'Orgãos '
'Municipais '
'Pg. Municipal da Casa Civil, matrícula 49327-9,\n'
'SECRETARIA MUNICIPAL DA CASA '
'CIVIL 1\n'
' '
'devidamente habilitado pela CNH sob nº\n'
' '
'05084675850, categoria AB. Art. 2º A\n'
'SECRETARIA MUNICIPAL DE '
'ADMINISTRAÇÃO 1\n'
' '
'responsabilidade administrativa, civil e penal, em\n'
'SECRETARIA MUNICIPAL DA FAZENDA '
'2 caso de colisões, lesões '
'corporais ou mesmo óbitos\n'
'SECRETARIA MUNICIPAL DE TRANSPARÊNCIA,AUDITORIA '
'E decorrentes do objetivo desta '
[...]
Texto omitido porque é MUITA coisa
[...]
'Portaria, qual seja,\n'
'CONTROLE '
'4 autorizar a condução do '
'automóvel da Secretaria\n'
'SECRETARIA MUNICIPAL DE '
'EDUCAÇÃO 5 '
'Municipal da Casa Civil, conforme termo de\n'
'SECRETARIA MUNICIPAL DE '
'INFRAESTRUTURA 6 '
'\n'
'\n'
'\n'
'S.M.C.C.\n'
'SECRETÁRIO: EVERSON '
'MENDES CONTROLE: '
'THAMARA MALTA '
'TELEFONE: (48) 3251-6062\n'
'\x0c',
'territory_id': '4205407'}
Você pode deixar rodando até o robozinho baixar tudo, mas isso vai levar um tempinho. Para parar o robô, aperte Ctrl + c.
Agora dê uma olhada nos arquivos baixados em data/full:
jvanz@earth:~/serenata/diario-oficial> ls data/full/
000206dc56c5753213168d1aad67e6d925862c0b.doc 3f67f0c7ee0e054bd477dd585bcaf895c712a175.doc.txt 7f3e870070e45083e503cc9858068d0dd87af122.pdf.txt bf7f18a1e85067bee44f26cb5cd62274df08aa89.doc
000206dc56c5753213168d1aad67e6d925862c0b.doc.txt 3f6a9abc3115beaa26b20cd5e43f403a570c9a4e.doc 7f3fb482b9472f8fcc03c84090ee9825b19b9483.doc bf7f18a1e85067bee44f26cb5cd62274df08aa89.doc.txt
00067ca470afa2d2ac2f9fffc0bc4f6c9e9cc0ef.pdf 3f6a9abc3115beaa26b20cd5e43f403a570c9a4e.doc.txt 7f3fb482b9472f8fcc03c84090ee9825b19b9483.doc.txt bf7f52e8382df0d6ec569dae967018a07168c672.doc
00067ca470afa2d2ac2f9fffc0bc4f6c9e9cc0ef.pdf.txt 3f6b8276365051fce95e154c128d2cca300b2ea0.doc 7f45558c7ade30fecb2f3c068be633190953fb71.doc bf7f52e8382df0d6ec569dae967018a07168c672.doc.txt
000ce6ae16c71f4e082191be246d8f5b0925984e.doc 3f6b8276365051fce95e154c128d2cca300b2ea0.doc.txt 7f45558c7ade30fecb2f3c068be633190953fb71.doc.txt bf807874e9126e9c019490b236288c36d8622f43.pdf
000ce6ae16c71f4e082191be246d8f5b0925984e.doc.txt 3f6e379f971523a0827788f275ad606d1bec2f93.doc 7f49aafd3f51b330136164aca8170a26ab8c679e.doc bf807874e9126e9c019490b236288c36d8622f43.pdf.txt
0011b654ba29d6d4415908f1251245b4f7f3909e.doc 3f6e379f971523a0827788f275ad606d1bec2f93.doc.txt 7f49aafd3f51b330136164aca8170a26ab8c679e.doc.txt bf82c035df0480b351e5594baf9d55262562d307.doc
0011b654ba29d6d4415908f1251245b4f7f3909e.doc.txt 3f70de7787371b4b2676a61587a592239311988c.doc 7f5168d009b6c54d1f03f8663d56e5692fe29af1.doc bf82c035df0480b351e5594baf9d55262562d307.doc.txt
00139767bba460a2d731e7e08f69d1ad065d9d42.pdf 3f70de7787371b4b2676a61587a592239311988c.doc.txt 7f5168d009b6c54d1f03f8663d56e5692fe29af1.doc.txt bf8c5d2b8a0ffd03090a25d66791c9a58e1da1f5.doc
00139767bba460a2d731e7e08f69d1ad065d9d42.pdf.txt 3f7393fbda95cc315b50af2af0f22f11ffbf818a.doc 7f554d50573d1d4fb1106ca921ab810e6e928de1.doc bf8c5d2b8a0ffd03090a25d66791c9a58e1da1f5.doc.txt
00195ec0e20d47e36f9dd156652c971d01e996e3.pdf 3f7393fbda95cc315b50af2af0f22f11ffbf818a.doc.txt 7f554d50573d1d4fb1106ca921ab810e6e928de1.doc.txt bf8f2dc63020f0fd4d354a1780b5393dc88828c0.pdf
00195ec0e20d47e36f9dd156652c971d01e996e3.pdf.txt 3f77937f5e7cfa9e2019dec8b28cfc1d1e4f091e.doc 7f5bd9eb72d24d7ce3c40b1f8a8885c5cedc606a.doc bf8f2dc63020f0fd4d354a1780b5393dc88828c0.pdf.txt
Ótimo! Agora que você já rodou o robô. Está na hora de entendermos mais a fundo algumas partes que fazem isso tudo funcionar.
Python
Python é a linguagem de programação que utilizamos para escrever o nosso robô. Não pretendo me aprofundar muito em Python porque isso é um mundo gigantesco que, por si só, renderia muito e muitos artigos. Mas para ajudar aqueles que estão querendo aprender, sugiro alguns materiais que podem ser encontrados na Internet:
Tutorial realizado pelo Grupy Blumenau
Scrapy
Scrapy é a biblioteca que utilizamos para acessar, navegar e encontrar os que queremos nas páginas dos diários oficiais. Podemos dizer que é o coração do nosso robô. Essa lib faz o trabalho sujo que baixar e deixar disponíveis de maneira mais fácil os dados das páginas que estamos vasculhando.
Vamos dar uma olhada como é definido o nosso robô e a maneira de navegar pelas páginas web. Ah! Só para deixar claro, "spider" é o nome dados no scrapy para código que irá acessar e baixar os dados do site do diário oficial. Para exemplificar, vou utilizar a cidade de Florianópolis:
import re
from datetime import date, datetime
from dateparser import parse
from dateutil.relativedelta import relativedelta
from scrapy import FormRequest
from gazette.items import Gazette
from gazette.spiders.base import BaseGazetteSpider
class ScFlorianopolisSpider(BaseGazetteSpider):
name = "sc_florianopolis"
URL = "http://www.pmf.sc.gov.br/governo/index.php?pagina=govdiariooficial"
TERRITORY_ID = "4205407"
AVAILABLE_FROM = date(2015, 1, 1) # actually from June/2009
def start_requests(self):
target = date.today()
while target >= self.AVAILABLE_FROM:
year, month = str(target.year), str(target.month)
data = dict(ano=year, mes=month, passo="1", enviar="")
yield FormRequest(url=self.URL, formdata=data, callback=self.parse)
target = target + relativedelta(months=1)
def parse(self, response):
for link in response.css("ul.listagem li a"):
url = self.get_pdf_url(response, link)
if not url:
continue
yield Gazette(
date=self.get_date(link),
file_urls=(url,),
is_extra_edition=self.is_extra(link),
territory_id=self.TERRITORY_ID,
power="executive_legislature",
scraped_at=datetime.utcnow(),
)
@staticmethod
def get_pdf_url(response, link):
relative_url = link.css("::attr(href)").extract_first()
if not relative_url.lower().endswith(".pdf"):
return None
return response.urljoin(relative_url)
@staticmethod
def get_date(link):
text = " ".join(link.css("::text").extract())
pattern = r"\d{1,2}\s+de\s+\w+\s+de\s+\d{4}"
match = re.search(pattern, text)
if not match:
return None
return parse(match.group(), languages=("pt",)).date()
@staticmethod
def is_extra(link):
text = " ".join(link.css("::text").extract())
return "extra" in text.lower()
Nas primeiras linhas do script estamos dizendo ao Python o que vamos utilizar. Por hora, vamos ignora-las e focar no spider. A brincadeira começa a ficar séria a partir da linha class ScFlorianopolisSpider(BaseGazetteSpider). Não quero entrar em muito detalhes de programação, mas podemos dizer que uma class (ou classe em português), neste caso, é uma representação de de como iremos navegar e baixar os dados das páginas de internet. As linhas seguintes são:
name = "sc_florianopolis"
URL = "http://www.pmf.sc.gov.br/governo/index.php?pagina=govdiariooficial"
TERRITORY_ID = "4205407"
AVAILABLE_FROM = date(2015, 1, 1) # actually from June/2009
O atributo name diz qual é o nome do spider. Lembra quando rodamos o spider a primeira vez? Então, nós passamos o nome do spider que queríamos rodar. É baseado nesse nome que o scrapy encontra e executa o spider.
URL é um atributo que guarda a primeira página que será visitada quando quisermos pegar os dados de Floripa. Veremos como essa informação é utilizada daqui a pouco. TERRITORY_ID é o código do IBGE da cidade que esse spider está extraindo os dados. AVAILABLE_FROM é algo especifico desse spider. A data colocada nesse atributo diz ao robozinho desde qual data ele deve procurar os arquivos do diário oficial. Uma informação importante, URL, AVAILABLE_FROM e TERRITORY_ID não são campos utilizados pelo scrapy. Eles são usados no código escrito pelas pessoas que criaram esse spider.
def start_requests(self):
target = date.today()
while target >= self.AVAILABLE_FROM:
year, month = str(target.year), str(target.month)
data = dict(ano=year, mes=month, passo="1", enviar="")
yield FormRequest(url=self.URL, formdata=data, callback=self.parse)
target = target + relativedelta(months=1)
O scrapy espera que o as classes definidas possuam alguns métodos para que possa funcionar corretamente. Quando um spider vai ser executado, o scrapy chama o método start_requests para saber qual é a primeira página que ele deve baixar. Note que o método start_requets retorna um objeto FormRequest. Nesse caso, ele representa uma request que deve ser feita. O scrapy permite que você retorne outros valores nesse método. Mas por motivos de simplicidade, vamos deixar isso para outra hora. O que for baixado da request retornada pelo start_requests é processado e passado para o método parse:
def parse(self, response):
for link in response.css("ul.listagem li a"):
url = self.get_pdf_url(response, link)
if not url:
continue
yield Gazette(
date=self.get_date(link),
file_urls=(url,),
is_extra_edition=self.is_extra(link),
territory_id=self.TERRITORY_ID,
power="executive_legislature",
scraped_at=datetime.utcnow(),
)
Note que o método parse recebe como parametro um objeto. Esse objeto, que neste caso é chamado de response, é o que contem o que foi baixado pelo scrapy daquela requisão que você retornou anteriormente no método start_requets. É aqui que a mágica acontece. É nesse método que você define como nosso robô vai achar os arquivos do diário oficial. Vamos destrinchar o que está acontecendo aqui.
Logo no início do método é chamado uma função chamada css. CSS é uma forma que podemos utilizar para encontrar elementos na página. Nesse exemplo, estamos procurando listas não numeradas, que tenham a classe (classe do CSS, não é a mesma classe do python) listagem e pegando os links que existem nos itens dessa lista. Sei que é um pouco complicado de entender no primeiro momento. Mas logo a seguir teremos uma sessão só para explicar isso. ;)
Uma vez com os link disponíveis da lista, para cada um deles chamamos o método get_pdf_url que irá extrair os link dos arquivos do diário oficial. Uma vez com o link, nós retornamos um objeto Gazette. Um objeto nada mais é do que uma instanciação em memória de uma classe. Lembra da classe que vimos que ensina o nosso robô a encontrar os arquivos, a ScFlorianopolisSpider? Então, o scrapy instância essa classe e chamar seus métodos. Não se preocupe se não compreendeu isso com 100%. Você vai aprendendo conforme for programando.
Voltando ao Gazette... da mesma forma que o ScFlorianopolisSpider é uma classe que representa a "inteligência" de como o nosso robô sabe baixar os arquivos do diário oficial de Floripa. O Gazette representa um arquivo do diário oficial encontrado. Essa classe possuir alguns atributos que servem para identificar o arquivo. Como a date que é a data do diário oficial, file_urls contem o link para os arquivos do diário, territory_id é o identificador do município no IBGE, power diz de qual Poder é o documento. O scraped_at mostra qual é a data que o arquivo foi baixado.
Não sei se você notou que existem mais métodos não citados até agora. São métodos que foram criados para serem utilizados nos métodos citados. Dê uma olhada nele e veja se consegue entender o que eles fazem. Se estiver com dúvidas, não deixe de perguntar nos canais de comunicação dos embaixadores ou me pergunte pelas redes sociais que você pode encontrar aqui no meu blog.
Continuando... conseguimos baixar a página do diário oficial e encontrar os arquivos. Mas a primeira página do diário não tem todos os arquivos. Precisamos continuar navegando pelas páginas para baixar os que faltam. Temos duas opções:
Retorna um objeto request na função parse.
Quando o scrapy chama o método parse, ele espera de retorno um objeto de que representa uma requisição a outra página, o mesmo tipo de objeto retornado pelo start_requests, um item (como o Gazette), ou ainda uma lista/iterável de ambos. Isso significa que se retornarmos um objeto que represente uma requisição, o scrapy irá baixar a página e chamar a função parse novamente. Se retomarmos um item (Gazette) o scrapy assume que achamos o que estávamos procurando e passa esse item para o próximo passo na nossa linha de execução. Que nesse caso, é transformar os arquivos em texto e gravar as informações em um banco de dados.
Quando o método parse retornar nada, significa que já achamos tudo o que queremos e nosso robô pode parar e recarregar as baterias.
Retornar uma lista/iterável na função start_requets
Dê uma olhada no start_requets novamente. Note que é usado a palavra reservada yield ao invés de return. Isso significa que o método é uma função geradora. O que isso quer dizer? Novamente, simplificando bastante, é como se o retorno da função fosse tratado como uma lista. Isso faz que quando o scrapy chamar o next no retorno da start_request a execução irá continuar a partir de onde o yield anterior foi chamado. Ou seja, enquanto o start_request não retorna None ou uma lista finita de itens, o scrapy continuará baixando as páginas das URL retornadas pela função start_requests. Entenda mais sobre isso no video do Python para Zumbies
Alias! Perceba que a função parse também é uma função geradora. ;)
PS: No momento dessa escrita, o spider do Floripa tem um bug. O spider nunca termina.
Pipeline
Vamos voltar ao que acontece depois que retornamos um item, um arquivo do diário oficial. Uma vez que encontramos algo que estávamos procurando o scrapy passa esse item por uma série de procedimentos definidos em um arquivo de configuração. No scrapy, essa séria de procedimentos é chamada de pipeline. Todos os procedimentos executados nesse pipeline estão definidos no arquivo processing/data_collection/gazette/pipelines.py. Lá você vai ver o PostgreSQLPipeline que é a etapa que grava aquelas informações que você definiu la no objeto Gazette retornado pela função parse no banco de dados. Existe o GazetteDateFilteringPipeline que ignora os arquivos do diário oficial anteriores a uma data determinada no spider. Vai ver também o ExtractTextPipeline é o passo que extrai o texto dos arquivos de PDF, doc e texto.
Se tudo isso funcionar como o esperado. No final você terá diversos arquivos na pasta data/full. :-)
HTML, CSS e XPATH
HTML
HTML é como são definidas as página web. Por exemplo, esse é uma página web muito simples que você pode salvar em uma arquivo HTML local e abrir em seu navegador:
<html>
<head>
<title> Esse é o título da nossa página! </title>
</head>
<body>
Esse é corpo da página.
<a href="https://www.google.com">LInk para o google</a>
</body>
</html>
É isso com esse tipo de dados que iremos trabalhar dentro do spiders para achar e detectar os arquivos que estamos procurando.
CSS
Anteriormente comentei que CSS poderia ser utilizado para encontrar os arquivos dos diários oficiais que estamos procurando. Isso não é totalmente correto. CSS é muito mais que isso. De uma forma beeeeem resumida, CSS é o que deixa as páginas da rede mundial de computadores bonitas! ;-)
O que nós usamos estamos utilizando são os seletores CSS. Os seletores são utilizados para identificar os elementos da página que queremos modificar. Por exemplo, podemos utilizar seletores para dizer que todas as listas da minha página terão fundo preto e letras verdes. No nosso caso, não utilizamos os seletores para modificar o visual, mas sim, para achar os elementos que nos interessam. Você pode brincar com isso agora mesmo no seu navegador. Vou utilizar o mesmo seletor e página que estamos estudando até agora.
No seu navegador acesse esse link: http://www.pmf.sc.gov.br/governo/index.php?pagina=govdiariooficial.
Se a página não mudou desde quando escrevi esse artigo você deverá estar vendo algo parecido com isso:
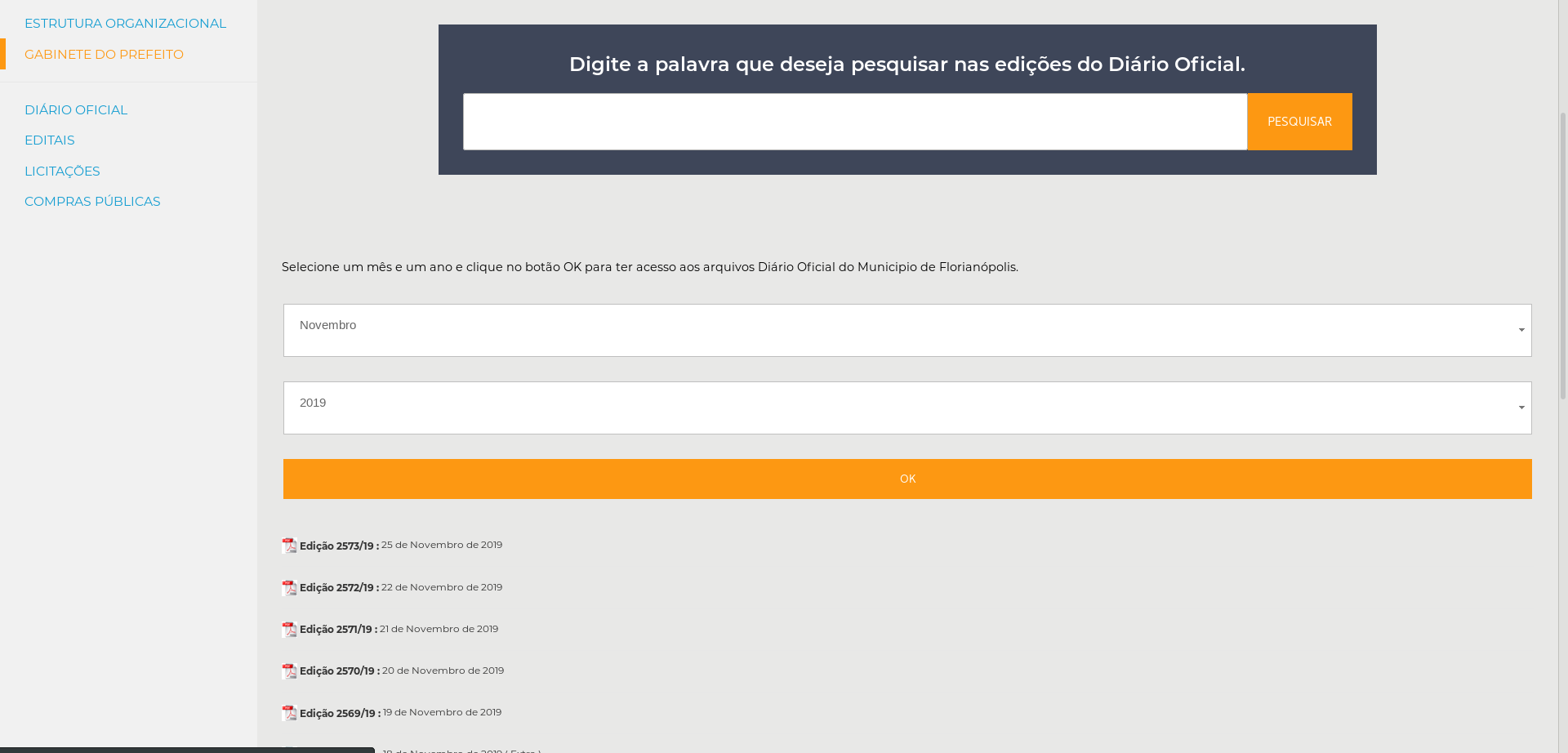
Legal, agora vamos brincar com os seletores. Vou utilizar o Firefox, mas o procedimento é muito parecido em outros navegadores. Clique com o botão direito na página e clique na opção "Inspecionar elemento". Agora você deverá estar vendo algo parecido com isso, note que você pode ver o HTML da página(seta 2):
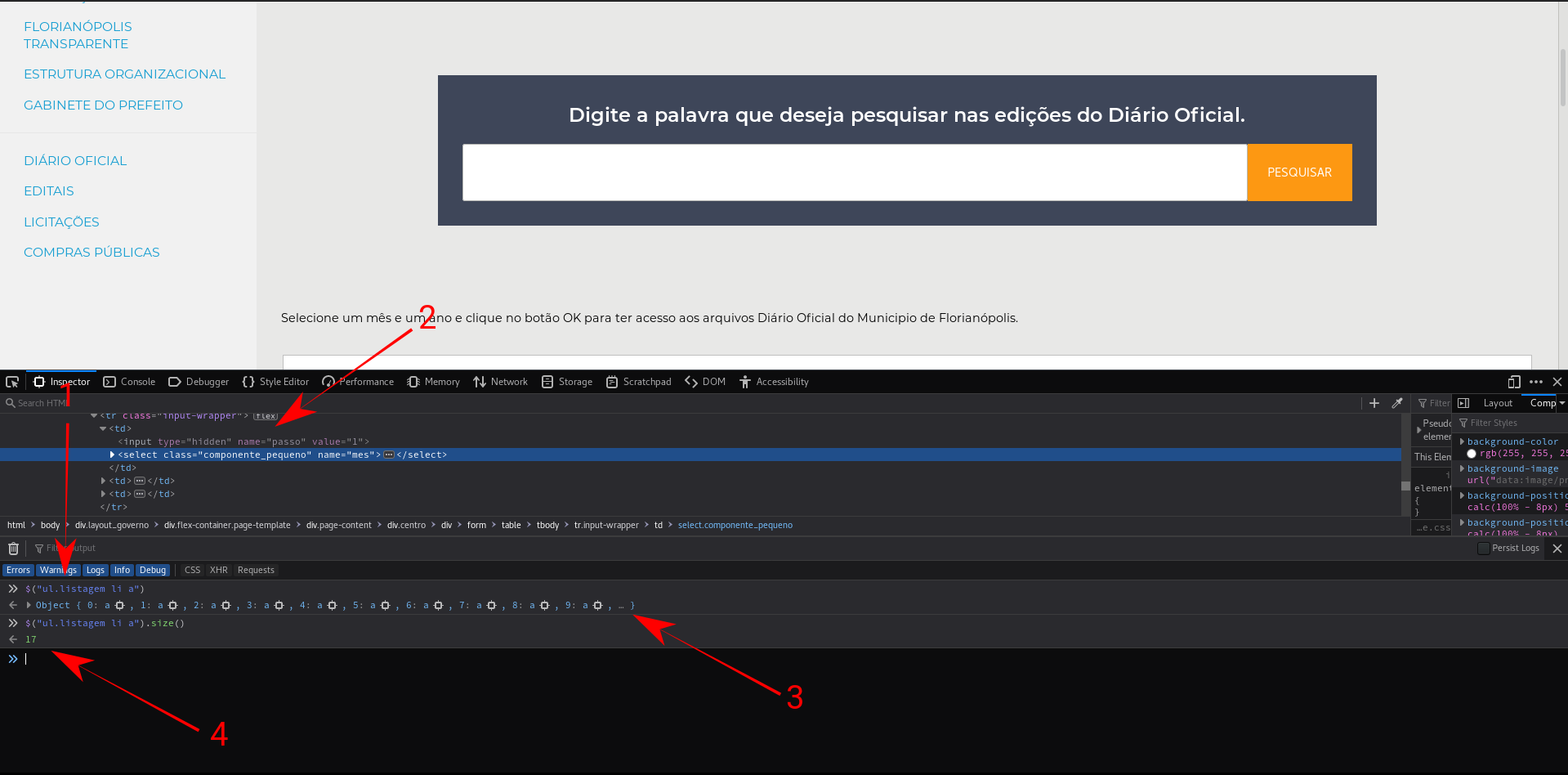
Nesssa tela podemos testar o nosso seletor CSS (seta 1) e ver o que ele encontrou (seta 3). Olha só que legal, encontramos 17 items (seta 4). Note que são exatamente os link para os arquivos que estamos procurando! São esses mesmos itens que são processados na função parse.
XPATH
Seletores CSS não são a única forma de você achar os elementos nas páginas. Você pode encontrar utilizando XPATH. Não vou entrar no XPATH nesse momento. Acho que o artigo já tem bastante coisa para todos que estiverem interessado em brincar com por um bom tempo. Além do que, os seletores CSS já podem resolver muitos, senão a maioria, dos casos. Mas para quem ficou interessado tem o seguinte link para a documentação da Mozilla